- Published on
Handling Race Condition in Distributed System
- 2 mins read
If you read the recent AWS outage summary, one cause was cited several times: race condition.
Let’s see what exactly it is — and how to prevent it in distributed environments.
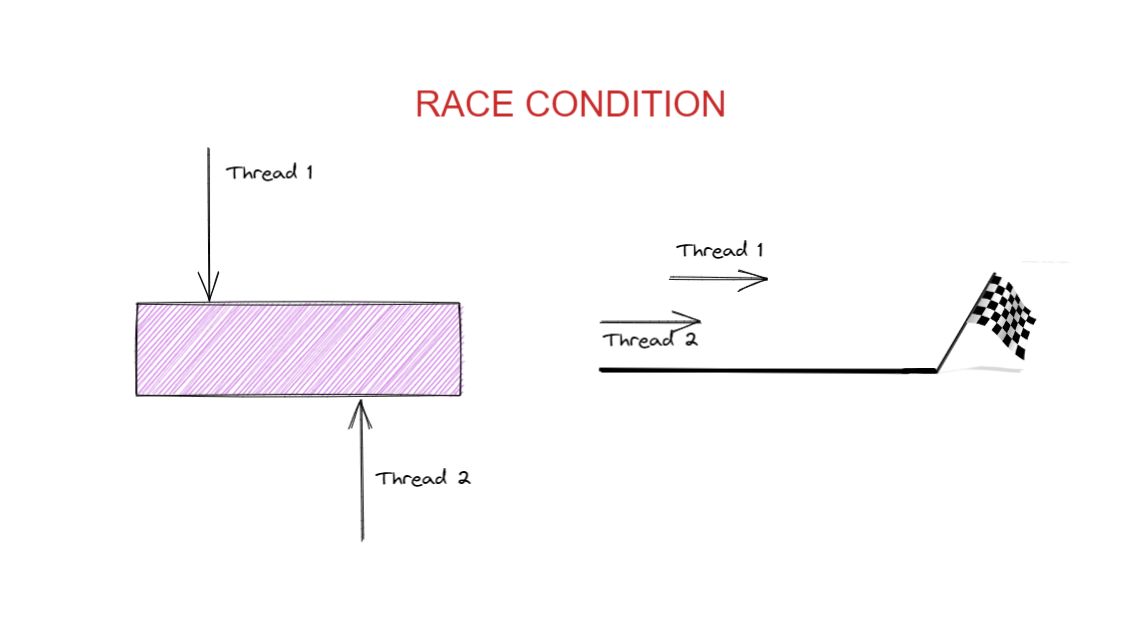
What is a Race Condition?
A race condition happens when two or more processes try to access or modify the same data at the same time, and the result depends on who finishes first.
In other words: It’s not the logic that’s wrong — it’s the timing. Imagine two users trying to withdraw money from the same bank account simultaneously. If both read the same balance before either updates it, the system might allow both withdrawals. That’s a race condition — and it’s one of the trickiest issues in distributed systems.
Why It Occurs?
Race conditions usually appear when your system becomes highly concurrent and distributed. Here are the 3 most common causes:
1️⃣ Concurrent Operations — Multiple services or threads try to read/update the same data at once.
2️⃣ Network Delays — One node acts on stale data because another update hasn’t propagated yet.
3️⃣ Lack of Synchronization — Critical sections of code aren’t properly protected, so operations overlap unpredictably.
How to Prevent It?
There’s no one-size-fits-all fix — only smarter strategies. Here are 3 powerful patterns that help prevent (or mitigate) race conditions in distributed environments:
1️⃣ Distributed Locks Tools like Zookeeper, Consul, or Redis Redlock ensure that only one process can modify a shared resource at a time.
Use with care — too many locks can slow your system.
2️⃣ Versioning & Atomic Operations Rely on timestamps or version numbers (like in MVCC databases).
Each write operation includes a version check to make sure no concurrent update has already modified the data.
3️⃣ Saga Pattern (for Long Transactions) Instead of one giant transaction, break it into smaller steps — each with its own rollback action.
If something fails midway, the system compensates automatically and returns to a consistent state.
📚 If you want to go deeper into this topic, I highly recommend “System Design Interview” by Alex Xu — one of the best resources to truly understand design system challenges.